共享单车
Contents
共享单车
说明
这次的文章参考自 https://zhuanlan.zhihu.com/p/36776526
提出问题
- 某城市中共享单车出租的需求量如何
- 消费者的消费习惯
- 影响租车人数的因素
理解数据
导入数据
origindata = CSV.read("data/bike-sharing/train.csv", DataFrame)
查看数据集信息
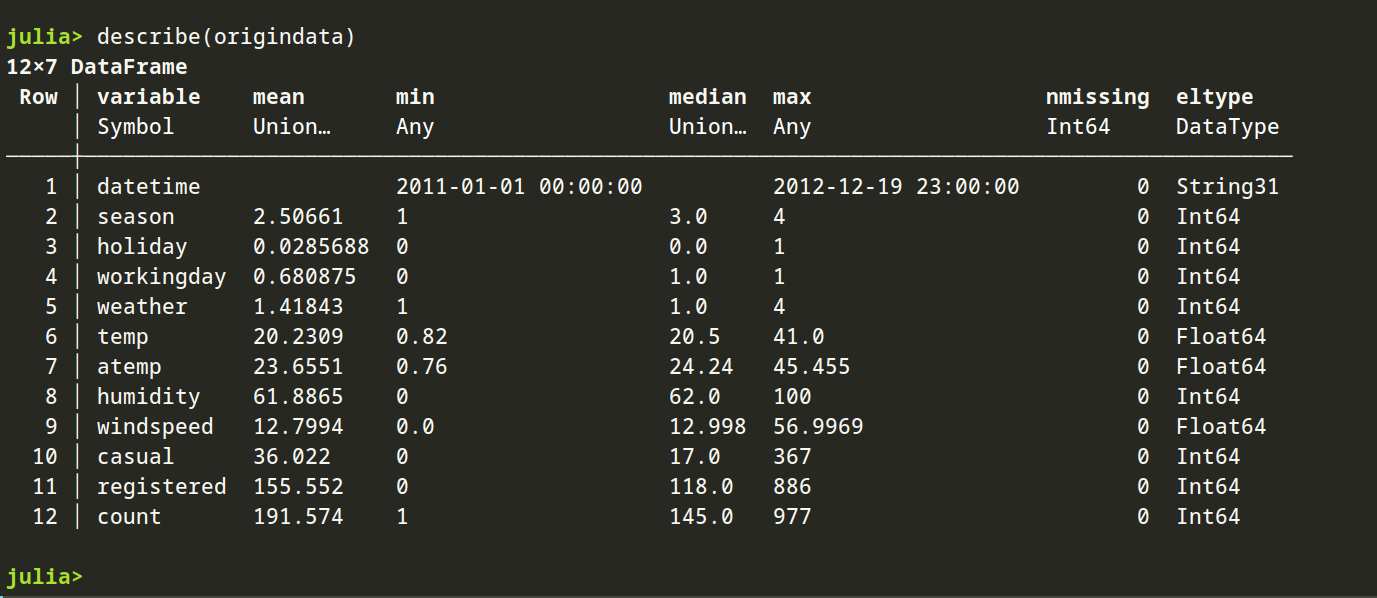
describe(origindata)
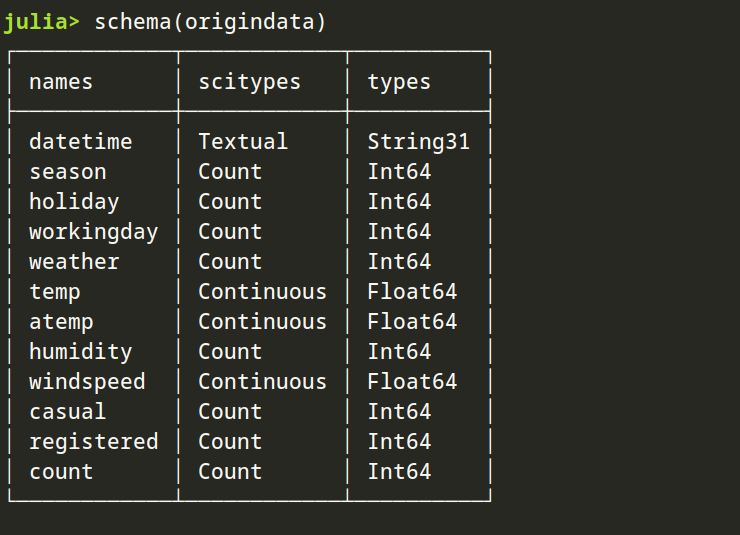
schema(data)
数据清洗
通过上面的数据查看,发现没有缺失值
数据类型转换
我们把 datetime 转换一下,转为
yearmonthweekdaydayhour
datetimes = map(x -> DateTime(x, "yyyy-mm-dd HH:MM:SS"), dataframe[!, :datetime])
years = map(year, datetimes)
months = map(month, datetimes)
days = map(day, datetimes)
weekdays = map(dayofweek, datetimes)
hours = map(hour, datetimes)
dataframe[!, :year] = years
dataframe[!, :month] = months
dataframe[!, :weekday] = weekdays
dataframe[!, :day] = days
dataframe[!, :hour] = hours
再转换季节,工作日,天气
seasonmap = Dict(1 => "Spring", 2 => "Summer", 3 => "Autumn", 4 => "Winter")
holidaymap = Dict(1 => "Workingday", 0 => "Weekday")
weathermap = Dict(1 => "Sunny", 2 => "Cloudy", 3 => "Flurry", 4 => "Heavy Snow")
dataframe[!, :season] = map(x -> seasonmap[x], dataframe[!, :season])
dataframe[!, :workingday] = map(x -> holidaymap[x], dataframe[!, :workingday])
dataframe[!, :weather] = map(x -> weathermap[x], dataframe[!, :weather])
封装成函数
function transformDataType!(dataframe::DataFrame)
# 转换日期
datetimes = map(x -> DateTime(x, "yyyy-mm-dd HH:MM:SS"), dataframe[!, :datetime])
years = map(year, datetimes)
months = map(month, datetimes)
days = map(day, datetimes)
weekdays = map(dayofweek, datetimes)
hours = map(hour, datetimes)
dataframe[!, :year] = years
dataframe[!, :month] = months
dataframe[!, :weekday] = weekdays
dataframe[!, :day] = days
dataframe[!, :hour] = hours
# 转换季节,工作日,天气
seasonmap = Dict(1 => "Spring", 2 => "Summer", 3 => "Autumn", 4 => "Winter")
holidaymap = Dict(1 => "Workingday", 0 => "Weekday")
weathermap = Dict(1 => "Sunny", 2 => "Cloudy", 3 => "Flurry", 4 => "Heavy Snow")
dataframe[!, :season] = map(x -> seasonmap[x], dataframe[!, :season])
dataframe[!, :workingday] = map(x -> holidaymap[x], dataframe[!, :workingday])
dataframe[!, :weather] = map(x -> weathermap[x], dataframe[!, :weather])
return dataframe
end
数据可视化
查看特征之间的关联程度
function plotHeatmap(dataframe::DataFrame)
_schema = schema(dataframe)
columns = collect(_schema.names)
scitypes = collect(_schema.scitypes)
columns = columns[scitypes .!= Textual]
cormatrix = cor(Matrix(select(dataframe, columns)))
heatmap(string.(columns), string.(columns), cormatrix) |> display
end
plotHeatmap(origindata)

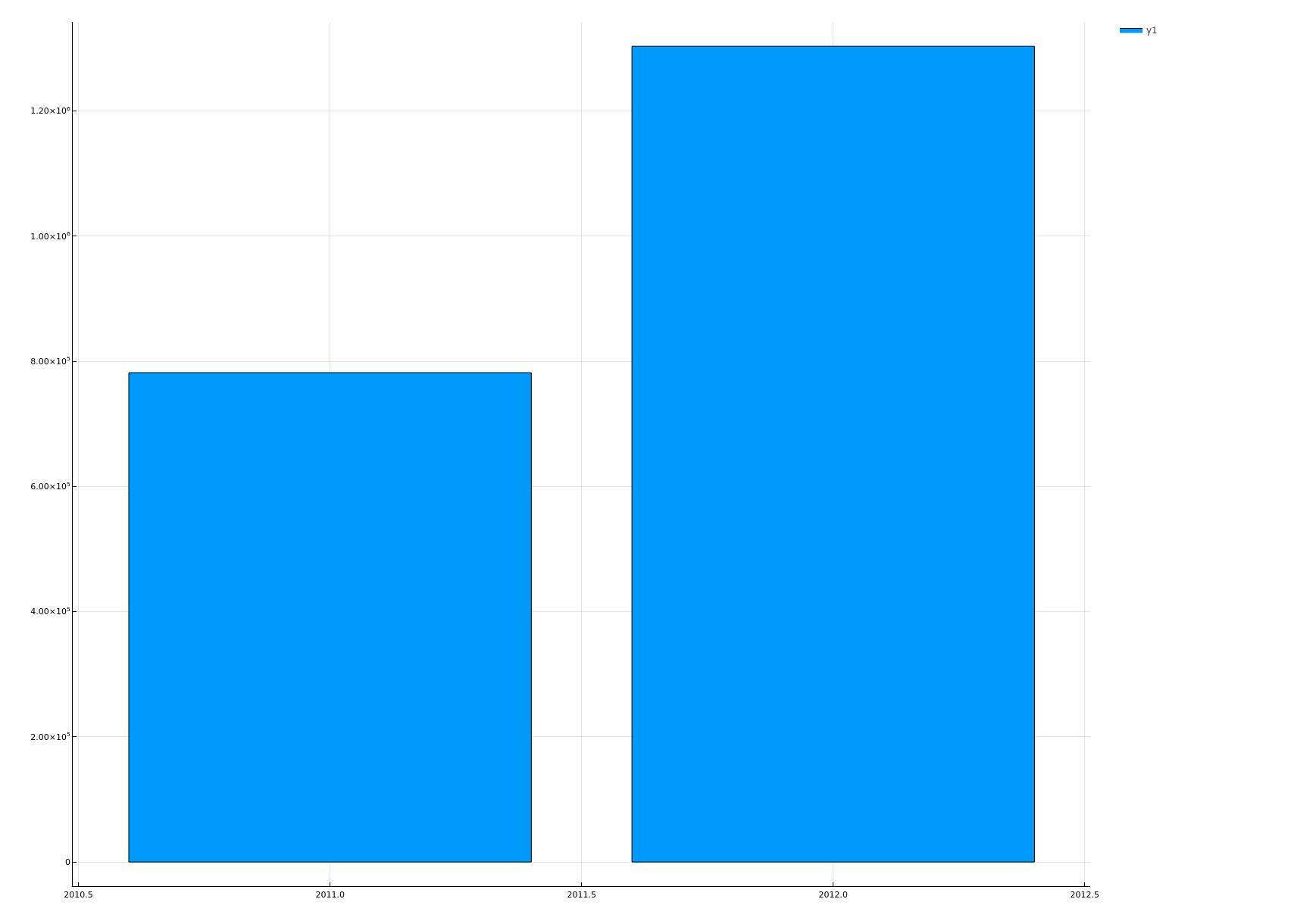
查看共享单车计划进展情况
function plotYearAndCount(dataframe::DataFrame)
groupDataframe = groupby(dataframe, :year)
years = Int[]
counts = Int[]
for _dataframe in groupDataframe
year = first(_dataframe[!, :year])
count = reduce(+, _dataframe[!, :count])
push!(years, year)
push!(counts, count)
end
bar(years, counts) |> display
end
plotYearAndCount(origindata)
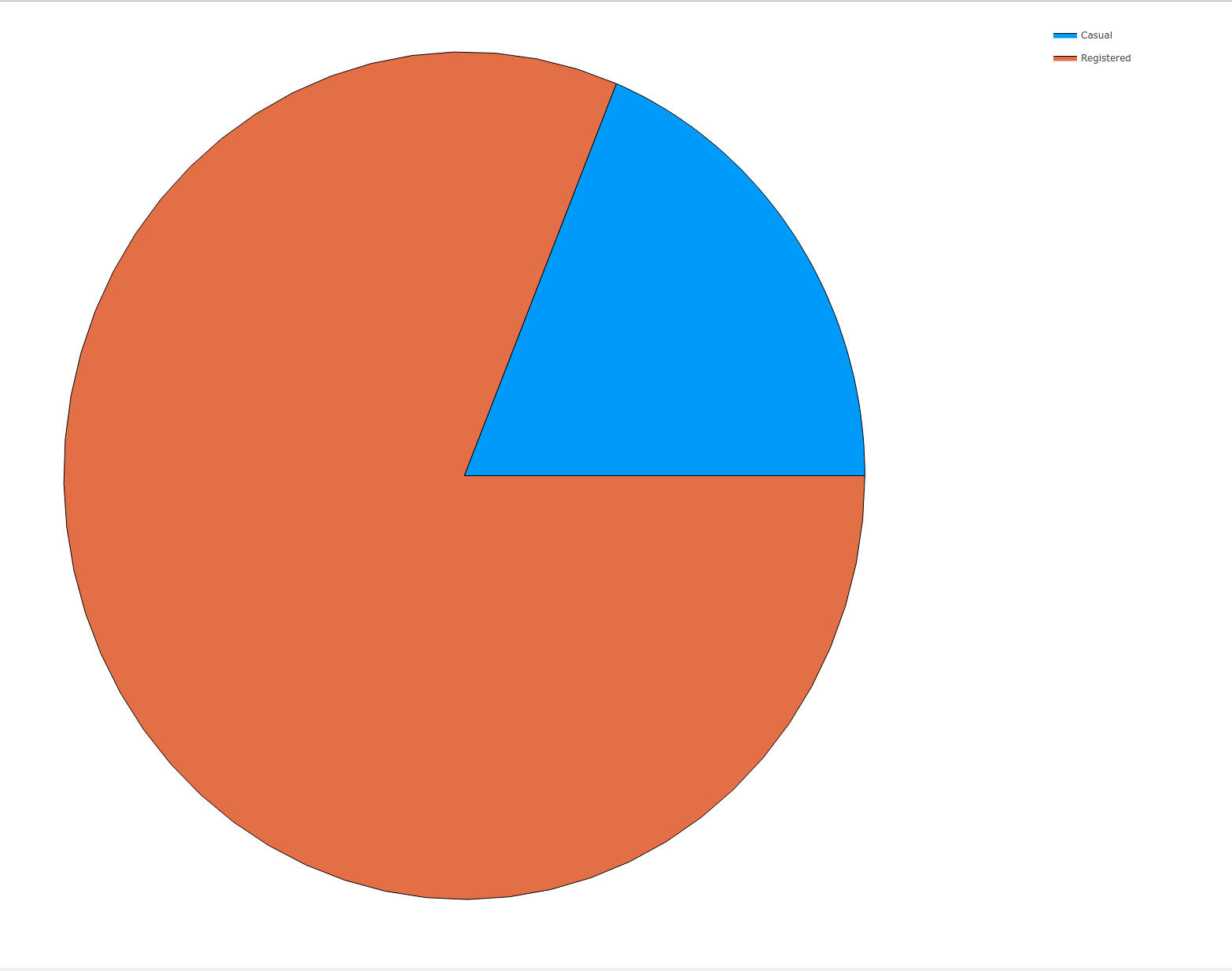
function plotPieOfCount(dataframe::DataFrame)
totalcount = reduce(+, dataframe[!, :count])
casualcount = reduce(+, dataframe[!, :casual])
registeredcount = reduce(+, dataframe[!, :registered])
xs = ["Casual", "Registered"]
ys = [casualcount / totalcount, registeredcount / totalcount]
pie(xs, ys) |> display
end
plotPieOfCount(origindata)
日期和时间与平均租车数关系
function plotTimeAndCount(dataframe::DataFrame, feature::Symbol)
features = [:hour, feature]
groupDataframe = groupby(dataframe, features)
hours = Int[]
counts = Float64[]
features = []
for _dataframe in groupDataframe
hour = first(_dataframe[!, :hour])
count = mean(_dataframe[!, :count])
_feature = first(_dataframe[!, feature])
push!(hours, hour)
push!(counts, count)
push!(features, _feature)
end
partcount = 24
p = plot()
for (_hours, _counts, labels) in Iterators.zip(Iterators.partition(hours, partcount),
Iterators.partition(counts, partcount),
Iterators.partition(features, partcount))
indexs = sortperm(_hours)
xs = _hours[indexs]
ys = _counts[indexs]
plot!(p, xs, ys, label = first(labels))
end
display(p)
end
plotTimeAndCount(origindata, :season)
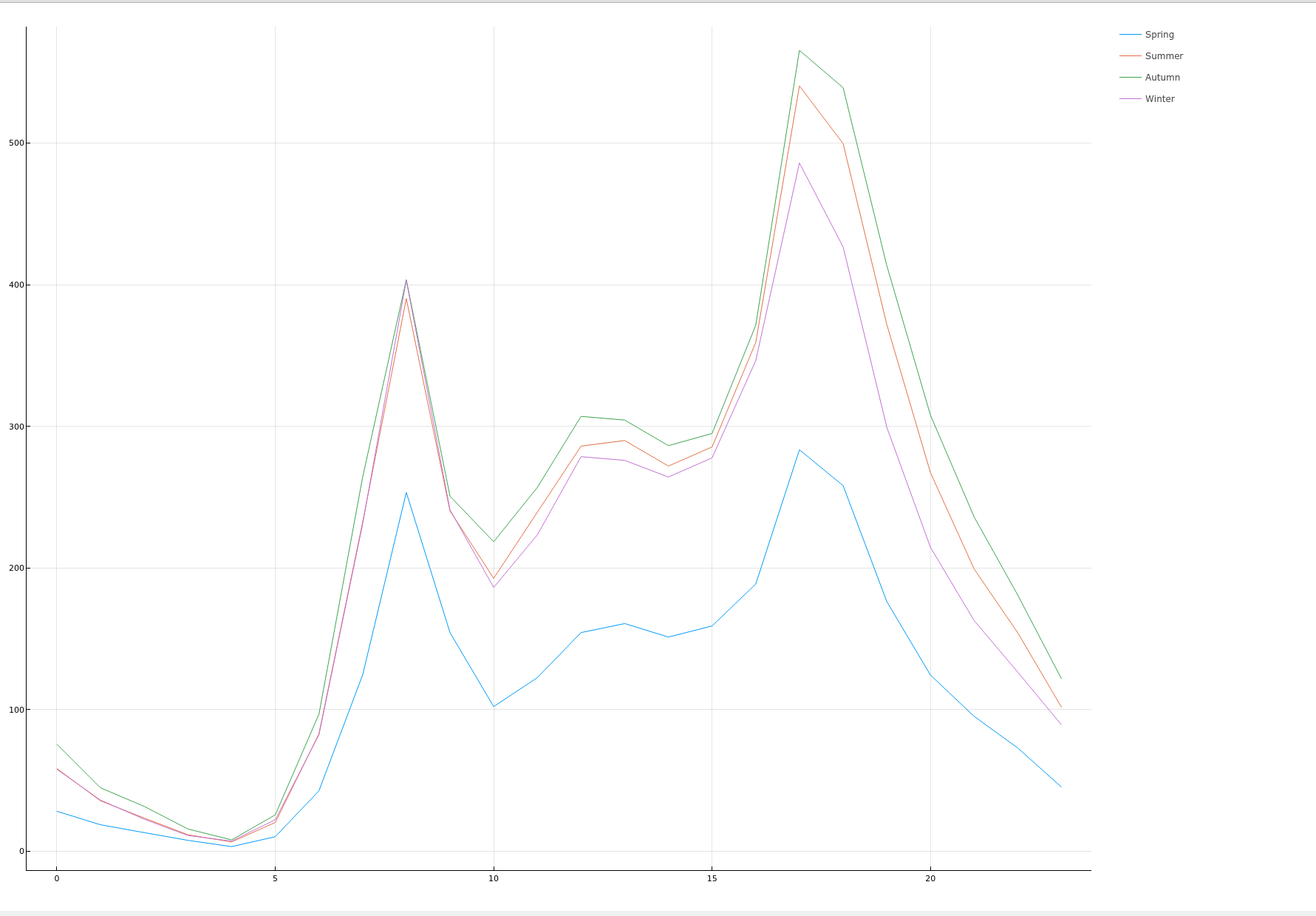
plotTimeAndCount(origindata, :workingday)
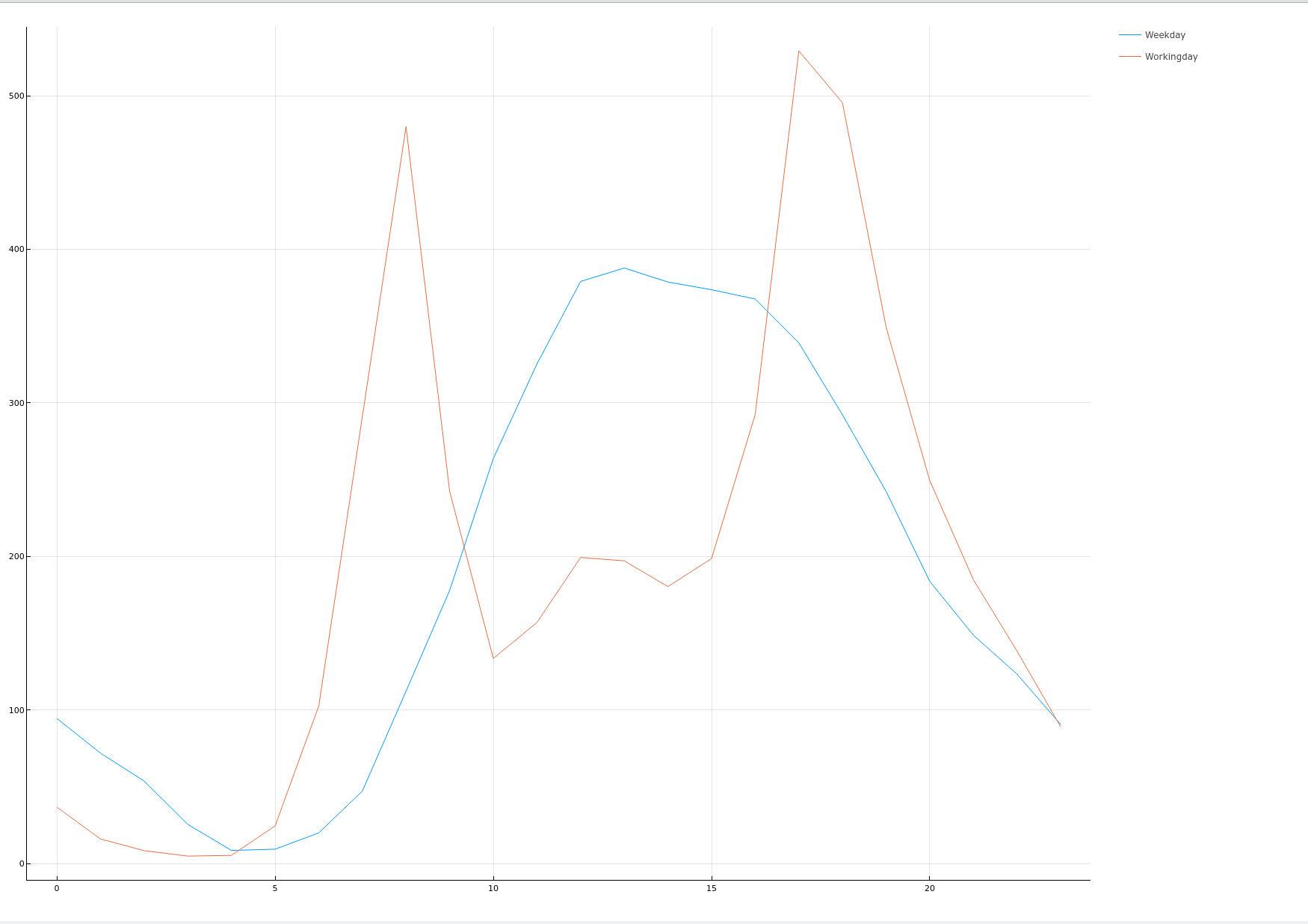
plotTimeAndCount(origindata, :weather)
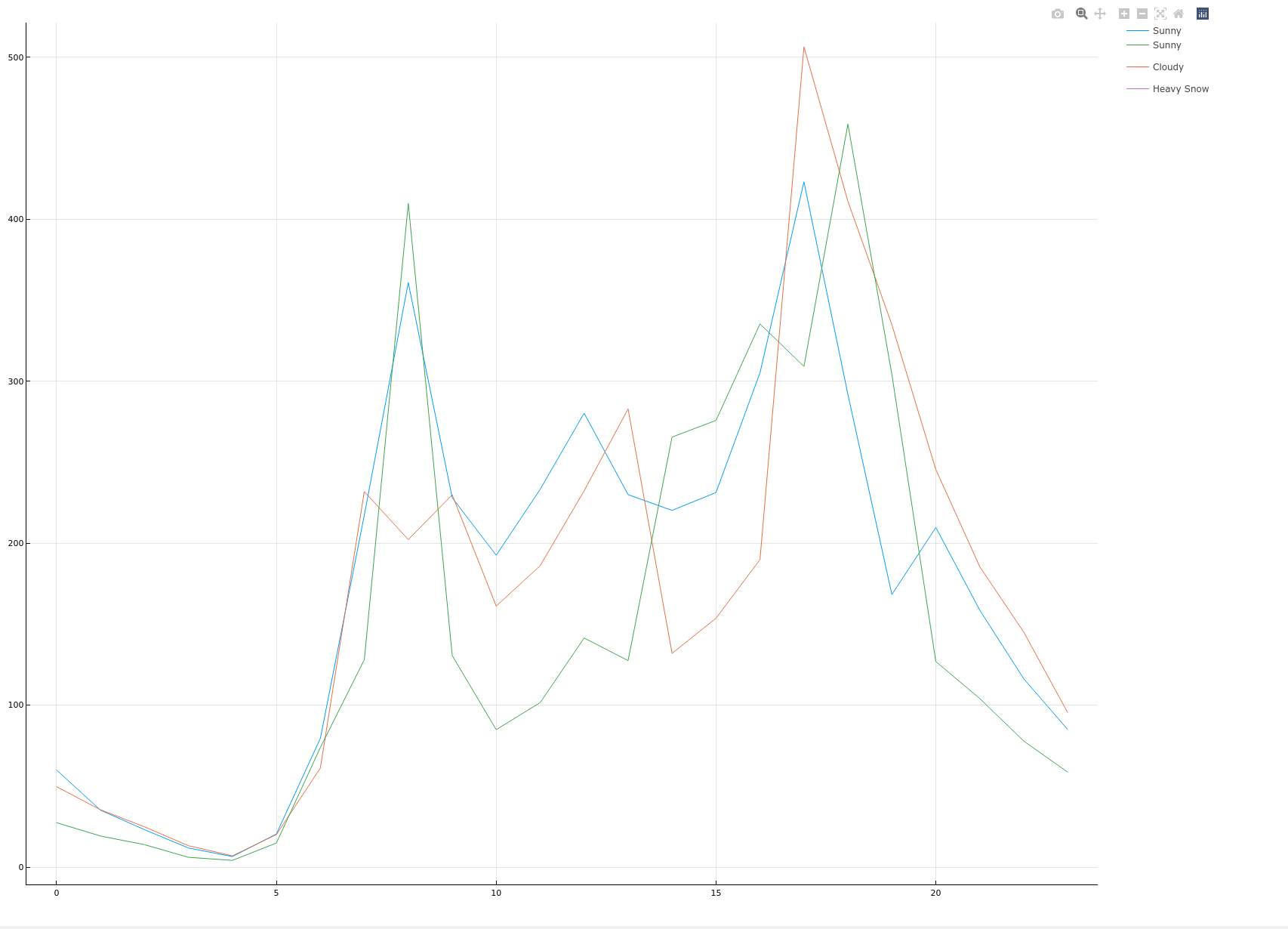
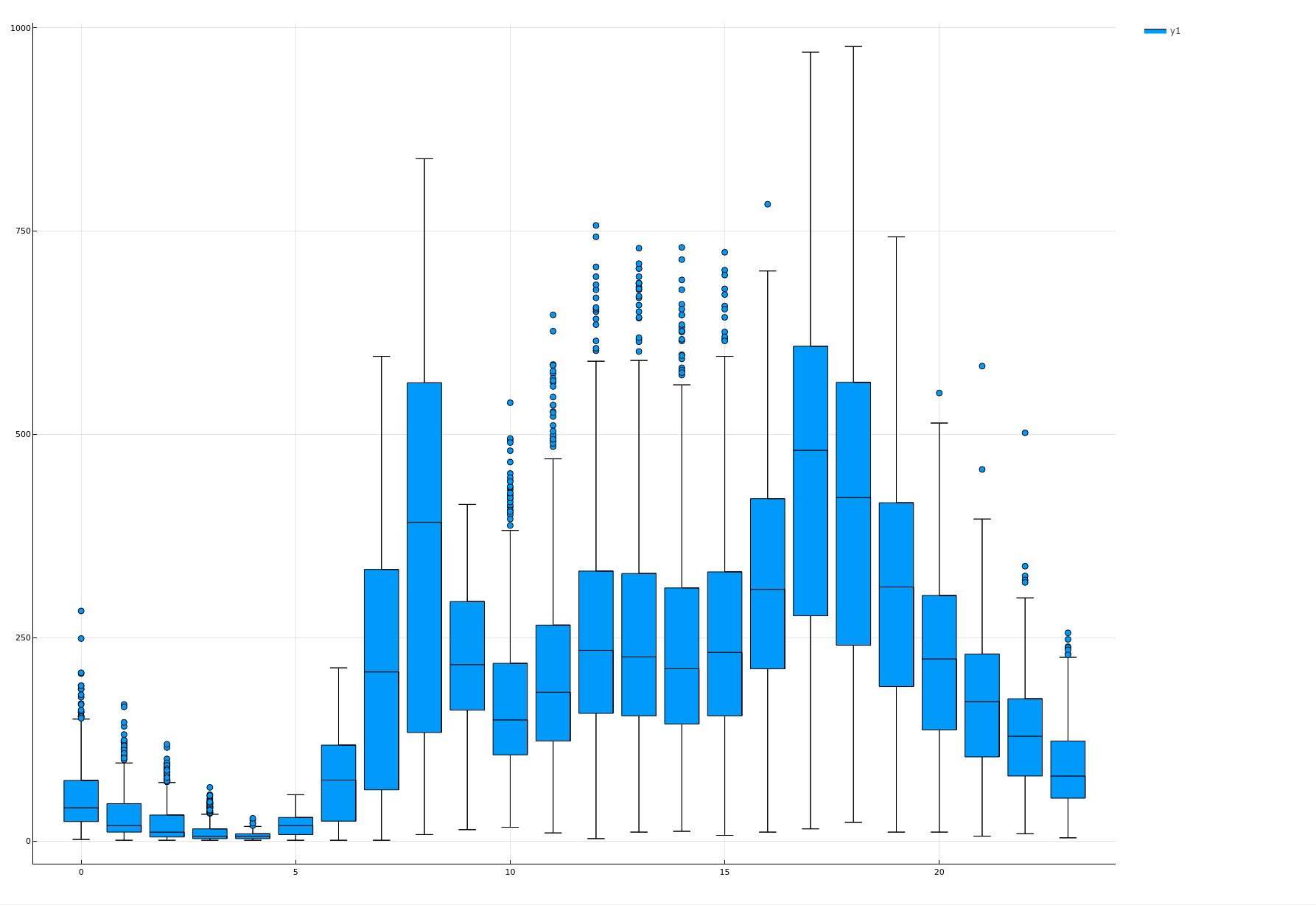
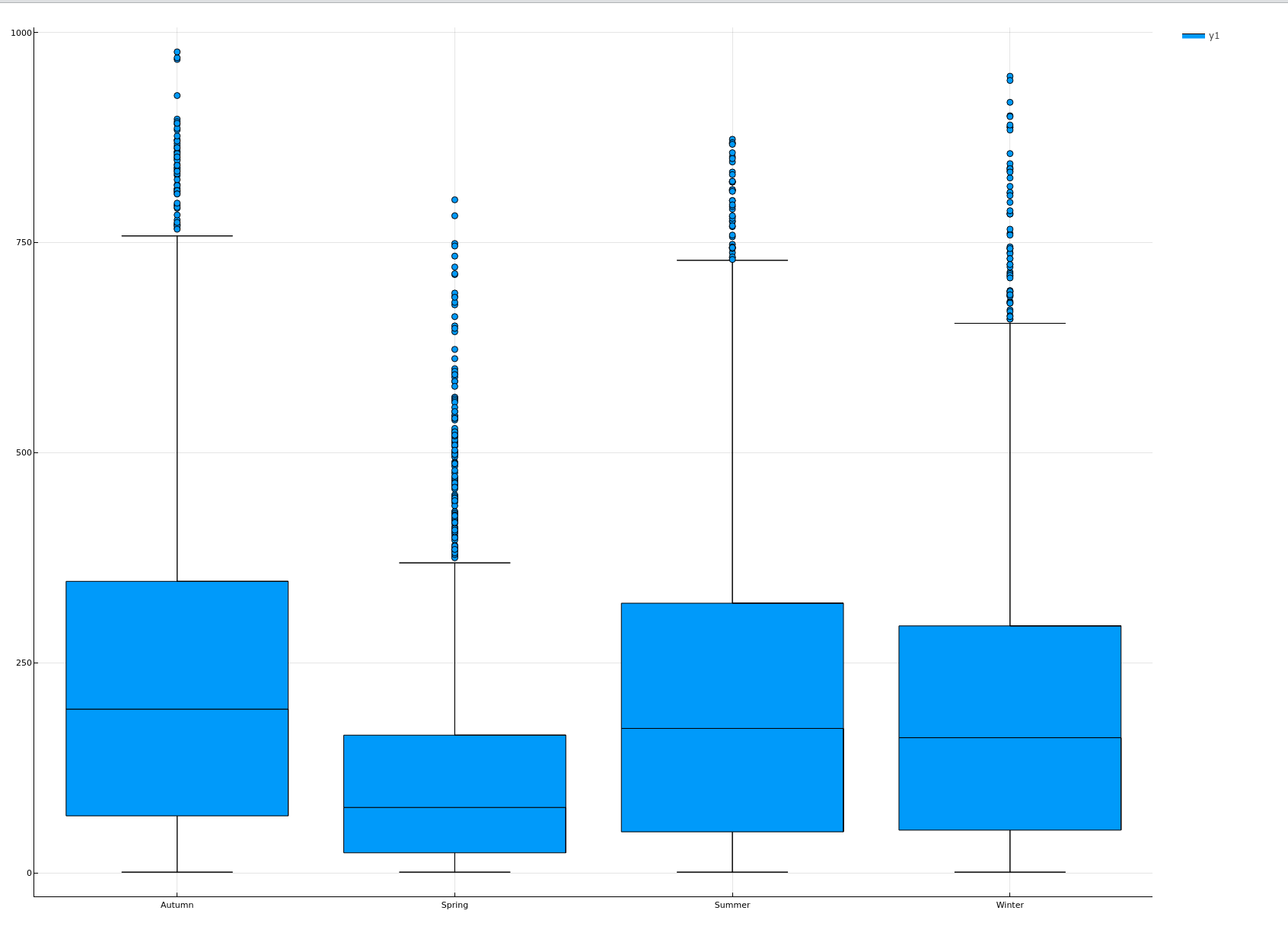
箱线图
查看每个小时租车数的箱线图
boxplot(origindata[!, :hour], origindata[!, :count]) |> display
查看每周租车数的箱线图
boxplot(origindata[!, :weekday], origindata[!, :count]) |> display
 查看每种天气租车数的箱线图
查看每种天气租车数的箱线图
boxplot(origindata[!, :weather], origindata[!, :count]) |> display
 查看每个季节租车数的箱线图
查看每个季节租车数的箱线图
boxplot(origindata[!, :season], origindata[!, :count]) |> display
预测
数据读取
traindata = CSV.read("data/bike-sharing/train.csv", DataFrame)
testdata = CSV.read("data/bike-sharing/test.csv", DataFrame)
数据转换
function fetchTransformedTrainData(traindata::DataFrame)
function transformDateTime!(dataframe::DataFrame)
datetimes = map(x -> DateTime(x, "yyyy-mm-dd HH:MM:SS"), dataframe[!, :datetime])
years = map(year, datetimes)
months = map(month, datetimes)
days = map(day, datetimes)
weekdays = map(dayofweek, datetimes)
hours = map(hour, datetimes)
dataframe[!, :year] = years
dataframe[!, :month] = months
dataframe[!, :weekday] = weekdays
dataframe[!, :day] = days
dataframe[!, :hour] = hours
return dataframe
end
featureSelector = FeatureSelector(
features = [:datetime, :casual, :registered],
ignore = true
)
onehotEncoder = OneHotEncoder(
features = [:season, :holiday, :workingday, :weather]
)
function coerceCount!(dataframe::DataFrame)
coerce!(dataframe, Count => Continuous)
return dataframe
end
transformModel = Pipeline(
transformDateTime!,
featureSelector,
onehotEncoder,
coerceCount!
)
transformMachine = machine(transformModel, traindata)
fit!(transformMachine)
# TODO 转换 traindata testdata
transformedTrainData = MLJ.transform(transformMachine, copy(traindata))
return transformedTrainData
end
function fetchTransformedTestData(testdata::DataFrame)
function transformDateTime!(dataframe::DataFrame)
datetimes = map(x -> DateTime(x, "yyyy-mm-dd HH:MM:SS"), dataframe[!, :datetime])
years = map(year, datetimes)
months = map(month, datetimes)
days = map(day, datetimes)
weekdays = map(dayofweek, datetimes)
hours = map(hour, datetimes)
dataframe[!, :year] = years
dataframe[!, :month] = months
dataframe[!, :weekday] = weekdays
dataframe[!, :day] = days
dataframe[!, :hour] = hours
return dataframe
end
featureSelector = FeatureSelector(
features = [:datetime],
ignore = true
)
function coerceCount!(dataframe::DataFrame)
coerce!(dataframe, Count => Continuous)
return dataframe
end
transformModel = Pipeline(
transformDateTime!,
featureSelector,
onehotEncoder,
coerceCount!
)
transformMachine = machine(transformModel, testdata)
fit!(transformMachine)
transformedTestData = MLJ.transform(transformMachine, copy(testdata))
return transformedTestData
end
模型训练
using MLJFlux, Flux, StableRNGs
mutable struct NetworkBuilder <: MLJFlux.Builder
n1::Int
n2::Int
n3::Int
n4::Int
end
function MLJFlux.build(model::NetworkBuilder, rng, nin, nout)
init = Flux.glorot_uniform(rng)
return Chain(
Dense(nin, model.n1, relu, init = init),
Dense(model.n1, model.n2, relu, init = init),
Dense(model.n2, model.n3, relu, init = init),
Dense(model.n3, model.n4, relu, init = init),
Dense(model.n4, nout, relu, init = init)
)
end
function fetchMachine(inputdata::DataFrame)
rng = StableRNG(1234)
regressor = NeuralNetworkRegressor(
lambda = 0.01,
builder = NetworkBuilder(10, 8, 6, 6),
batch_size = 5,
epochs = 600,
alpha = 0.4,
rng = rng
)
y, X = unpack(inputdata, colname -> colname == :count, colname -> true)
trainrow, testrow = partition(eachindex(y), 0.7, rng = rng)
regressorMachine = machine(regressor, X, y)
fit!(regressorMachine, rows = trainrow)
measure = evaluate!(regressorMachine,
resampling = CV(nfolds = 6, rng = rng),
measure = [l1, l2],
rows = testrow)
println(measure)
return regressorMachine
end
输出预测结果
function predictOuput(inputdata::DataFrame, inputtest::DataFrame)
mach = fetchMachine(inputdata)
output = MLJ.predict(mach, inputtest)
outputdataframe = DataFrame()
outputdataframe[!, :datetime] = testdata[!, :datetime]
outputdataframe[!, :count] = output
CSV.write("data/bike-sharing/submissing.csv", outputdataframe)
end
predictOutput(transformedTrainData, transformedTestData)
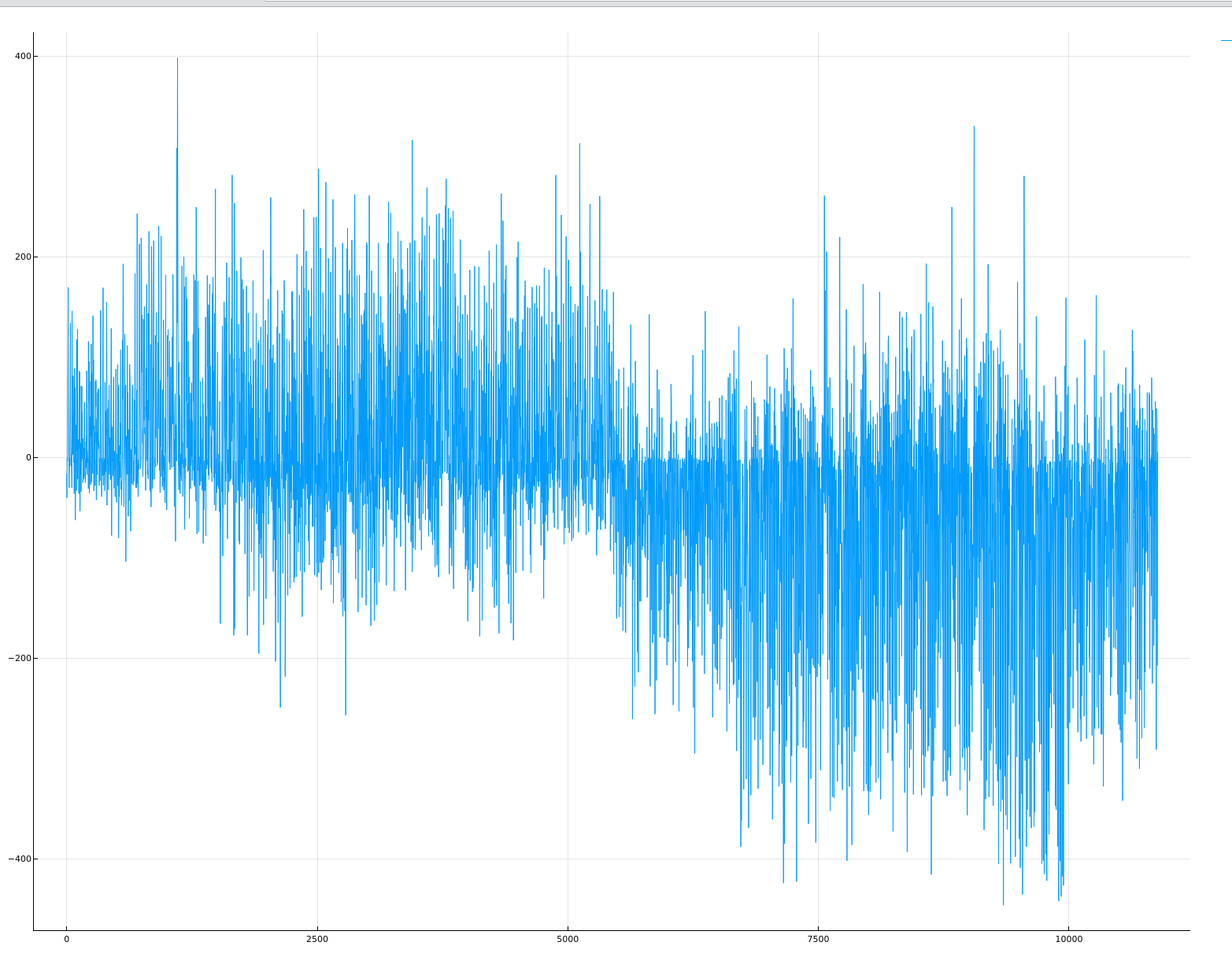
查看图线
这里我们看看预测的值与实际的值相差多少
function plotPrediction(dataframe::DataFrame, output::Vector)
difference = output .- dataframe[!, :count]
plot(difference) |> display
end
regressor = fetchMachine(transformedTrainData)
columns = names(transformedTrainData)
columns = columns[columns .!= "count"]
plotPrediction(transformedTrainData, MLJ.predict(regressor, select(transformedTrainData, columns)))
提交,查看成绩
 很遗憾,成绩不怎么样,别人都是0.3多少的
很遗憾,成绩不怎么样,别人都是0.3多少的
下一步
由于神经网络的训练速度实在太慢,调试参数要花费大量时间 下一步是寻找加速的方法,为训练加速