数据可视化 电影数据分析
Contents
数据可视化 电影数据分析
说明
这次的文章参考自 https://zhuanlan.zhihu.com/p/35453189
提出问题
简单分析制作一部电影时,应考虑哪些客观因素才能使电影成功? 为客户提供有效的数据一句,以便作出更准确 的决策 本次数据分析报告主要围绕一下几点进行分析
-
问题一:电影类型如何随时间发生变化?
- 电影数量上的对比
- 电影收入的对比
-
问题二:影响电影收入的客观因素有哪些? 这个不会,先放一放
-
问题三:两家电影公司Universal Pictures 和 Paramount Pictures之间的对比。
- 电影发行数量上的对比
- 电影产生的利润对比
-
问题四:改编电影和原创电影之间的对比。
- 电影发行数量上的对比
- 电影产生的利润对比
理解数据
重点关注的变量有:
imdb_idIMDB 标识号popularity在 Movie Database 上的相对页面查看次数budget预算(美元)revenue收入(美元)original_title电影名称cast演员列表,按 | 分隔,最多 5 名演员homepage电影首页的 URLdirector导演列表,按 | 分隔,最多 5 名导演tagline电影的标语keywords与电影相关的关键字,按 | 分隔,最多 5 个关键字overview剧情摘要runtime电影时长genres风格列表,按 | 分隔,最多 5 种风格production_companies制作公司列表,按 | 分隔,最多 5 家公司release_date首次上映日期vote_count评分次数vote_average平均评分release_year发行年份budget_adj根据通货膨胀调整的预算(2010 年,美元)revenue_adj根据通货膨胀调整的收入(2010 年,美元)
导入数据
using MLJFlux, Flux, MLJ, DataFrames, CSV, StatsBase, Dates
import JSON
creditsdata = CSV.read("data/movies/tmdb_5000_credits.csv", DataFrame)
moviesdata = CSV.read("data/movies/tmdb_5000_movies.csv", DataFrame)
select!(creditsdata, Not(:title))
fulldata = hcat(creditsdata, moviesdata)
使用 excel 查看数据
查看缺失值情况
for column in names(fulldata)
missingcount = count(ismissing, fulldata[!, column])
println("$column: \t $missingcount")
end
发现只有以下字段有缺失值
release_dateruntime
数据清洗
选择子集
columns = [:id, :title, :vote_average, :production_companies, :genres,
:release_date, :keywords, :runtime, :budget, :revenue, :vote_count, :popularity]
fulldata = select(fulldata, columns)
缺失值处理
fillReleaseDate(dataframe::DataFrame) = begin
mapdate(date::Union{Missing, Date}) = begin
if ismissing(date)
return Date("2014-06-01")
else
return date
end
end
dataframe[!, :release_date] = map(mapdate, dataframe[!, :release_date])
return dataframe
end
fillRuntime(dataframe::DataFrame) = begin
meanvalue = mean(skipmissing(dataframe[!, :runtime]))
mapruntime(runtime::Union{Missing, Float64}) = begin
if ismissing(runtime)
return meanvalue
else
return runtime
end
end
dataframe[!, :runtime] = map(mapruntime, dataframe[!, :runtime])
return dataframe
end
数据类型转换
-
在时间序列中提取年份
generateReleaseYear(dataframe::DataFrame) = begin dataframe[!, :release_year] = map(year, dataframe[!, :release_date]) return dataframe end
-
将电影类型添加到列,需进行one-hot编码
function generateGenreType(dataframe::DataFrame) len = first(size(dataframe)) for column in genrelist dataframe[!, column] = zeros(len) for row in eachrow(dataframe) if contains(row.genres, column) row[column] = 1 end end end return dataframe end
-
用年份索引
function sortByReleaseYear(dataframe::DataFrame) sort(dataframe, [:release_year]) end
数据转换
featureSelector = FeatureSelector(
features = [:release_date],
ignore = true
)
transformModel = Pipeline(
fillReleaseDate,
fillRuntime,
generateReleaseYear,
featureSelector,
generateGenreType,
sortByReleaseYear
# generateName
)
transformMachine = machine(transformModel, fulldata)
fit!(transformMachine)
transformedData = MLJ.transform(transformMachine, fulldata)
问题分析
电影类型随时间变化
-
提取电影类型
function fetchGenreList(dataframe::DataFrame) mapfn(array::Vector{Any}) = map(x -> x["name"], array) genrelist = Set{String}() jsons = map(JSON.parse, dataframe[!, :genres]) for json in jsons names = mapfn(json) for name in names push!(genrelist, name) end end return genrelist end const genrelist = fetchGenreList(fulldata)
-
对每个类型的电影按年份求和
function groupByReleaseYear(dataframe::DataFrame) dataframes = groupby(dataframe, :release_year) years = Int[] counts = Int[] for _dataframe in dataframes year = first(_dataframe.release_year) count = first(size(_dataframe)) push!(years, year) push!(counts, count) end bar(years, counts, xticks = :all, size = figuresize) |> display end groupByReleaseYear(transformedData)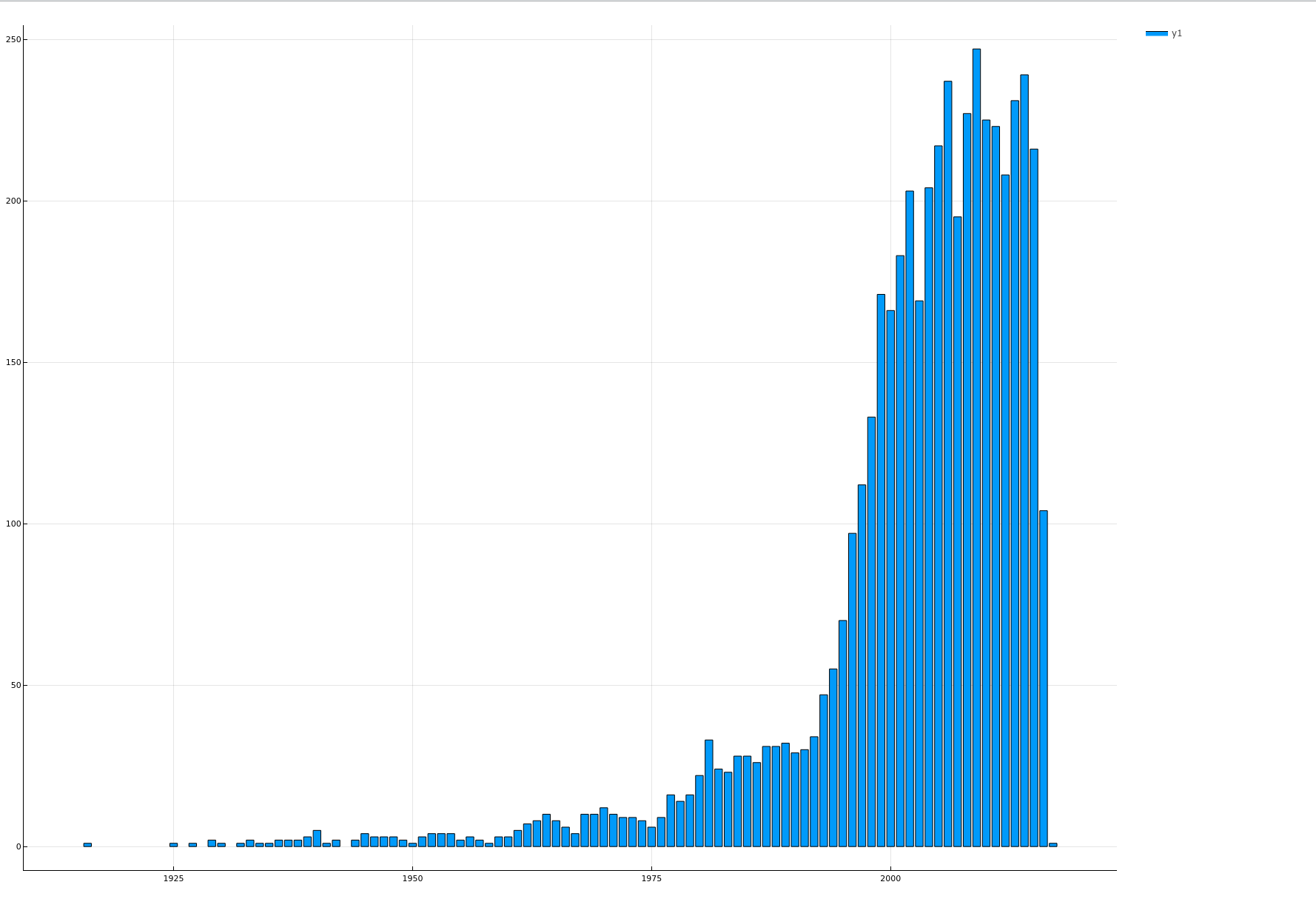
-
汇总各电影类型的总量
function groupByEachGenre(dataframe::DataFrame) record = Dict{String, Int}() for genre in genrelist record[genre] = 0 end for row in eachrow(dataframe) for genre in genrelist record[genre] += row[genre] end end xs = collect(keys(record)) ys = collect(values(record)) bar(xs, ys, xticks = :all, size = figuresize) |> display end groupByEachGenre(transformedData)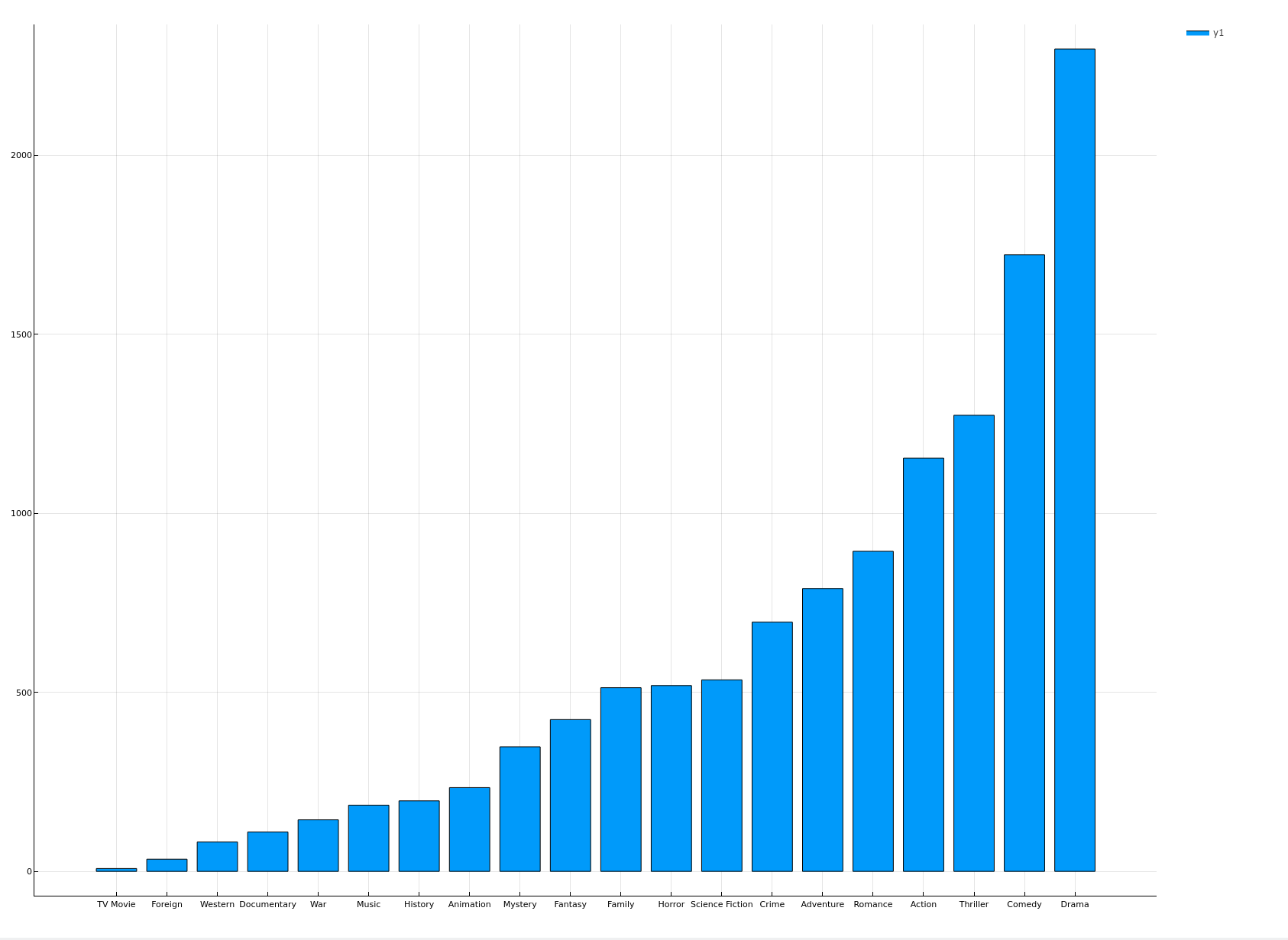
-
电影类型随时间的变化
function plotGenreAndTime(dataframe::DataFrame) columns = ["Drama","Comedy","Thriller","Action","Romance","Adventure", "Crime","Science Fiction","Horror","Family", "release_year"] _dataframes = groupby(select(dataframe, columns), :release_year) # p = plot() # record: Dict{year, Dict{Name, Count}} record = Dict{Int, Dict{String, Int}}() for _dataframe in _dataframes # years # counts year = first(_dataframe.release_year) record[year] = Dict{String, Int}() for column in columns[columns .!= "release_year"] record[year][column] = reduce(+, _dataframe[!, column]) end end _years = collect(keys(record)) _countmaps = collect(values(record)) indexs = sortperm(_years) years = _years[indexs] countmaps = _countmaps[indexs] p = plot(size = figuresize, xticks = :all) for column in columns[columns .!= "release_year"] counts = map(x -> x[column], countmaps) plot!(p, years, counts, label = column, xticks = :all) end plot(p) |> display end plotGenreAndTime(transformedData)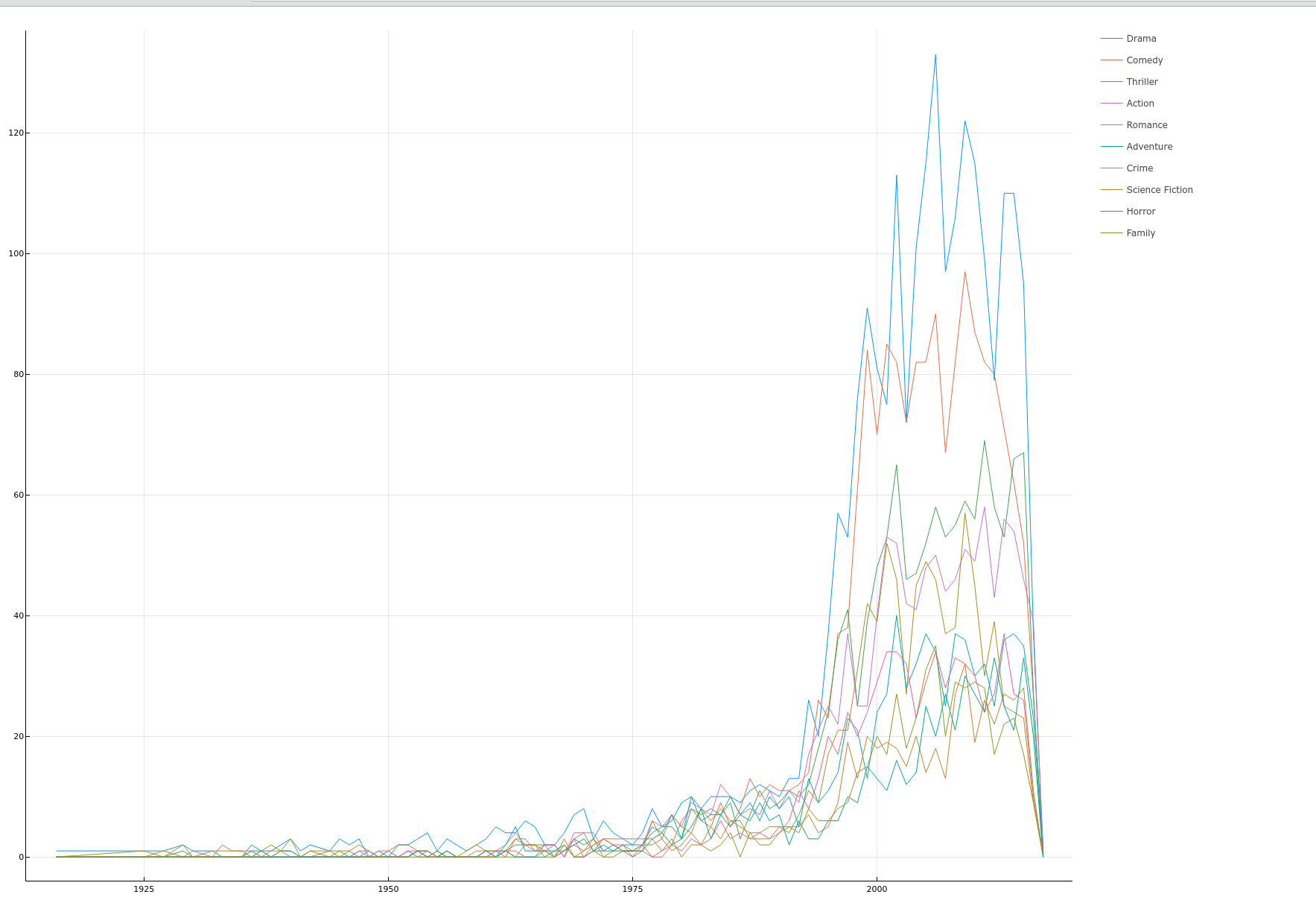
Universal Pictures和Paramount Pictures之间的对比
-
电影发行量对比
function plotCompareTotal(dataframe::DataFrame) dataframe[!, "Universal Pictures"] = map(s -> contains(s, "Universal Pictures") ? 1 : 0, dataframe[!, :production_companies]) dataframe[!, "Paramount Pictures"] = map(s -> contains(s, "Paramount Pictures") ? 1 : 0, dataframe[!, :production_companies]) universalTotal = reduce(+, dataframe[!, "Universal Pictures"]) paramountTotal = reduce(+, dataframe[!, "Paramount Pictures"]) total = universalTotal + paramountTotal xs = ["Universal Pictures", "Paramount Pictures"] ys = [universalTotal / total, paramountTotal / total] pie(xs, ys, aspect_ratio = 1.0) |> display companyDifference = groupby(select(dataframe, vcat(xs, "release_year")), :release_year) # record: Dict{Year, Dict{Company, Int}} record = Dict{Int, Dict{String, Int}}() for _dataframe in companyDifference year = first(_dataframe.release_year) record[year] = Dict{String, Int}() for column in xs count = reduce(+, _dataframe[!, column]) record[year][column] = count end end _years = collect(keys(record)) _countmaps = collect(values(record)) indexs = sortperm(_years) years = _years[indexs] countmaps = _countmaps[indexs] p = plot(size = figuresize) for column in xs counts = map(x -> x[column], countmaps) plot!(p, years, counts, label = column, xticks = :all) end plot(p) |> display end plotCompareTotal(transformedData)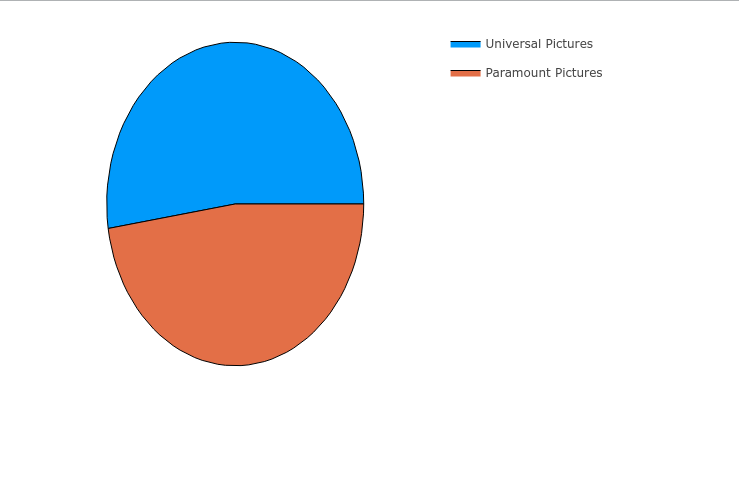
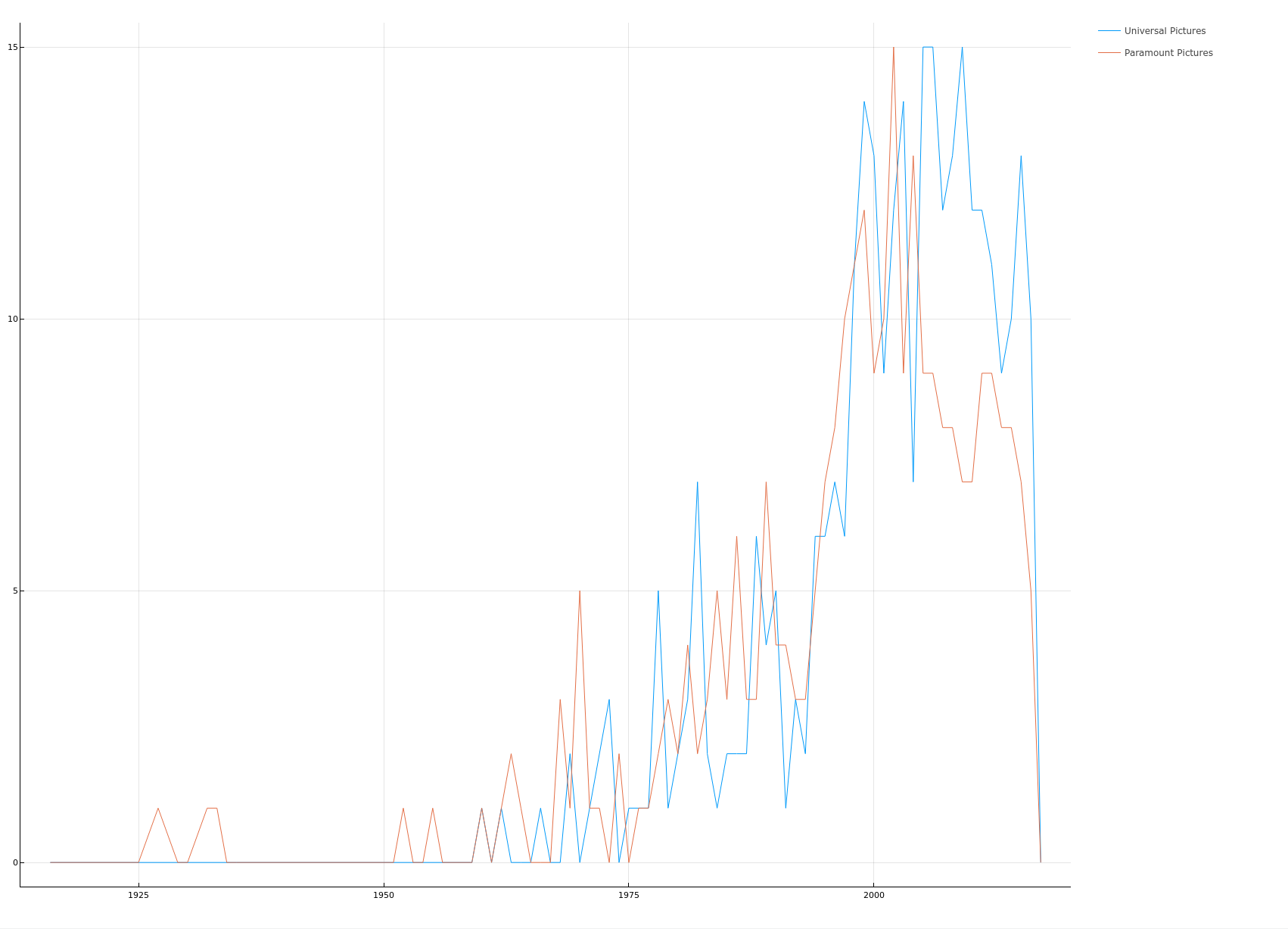
-
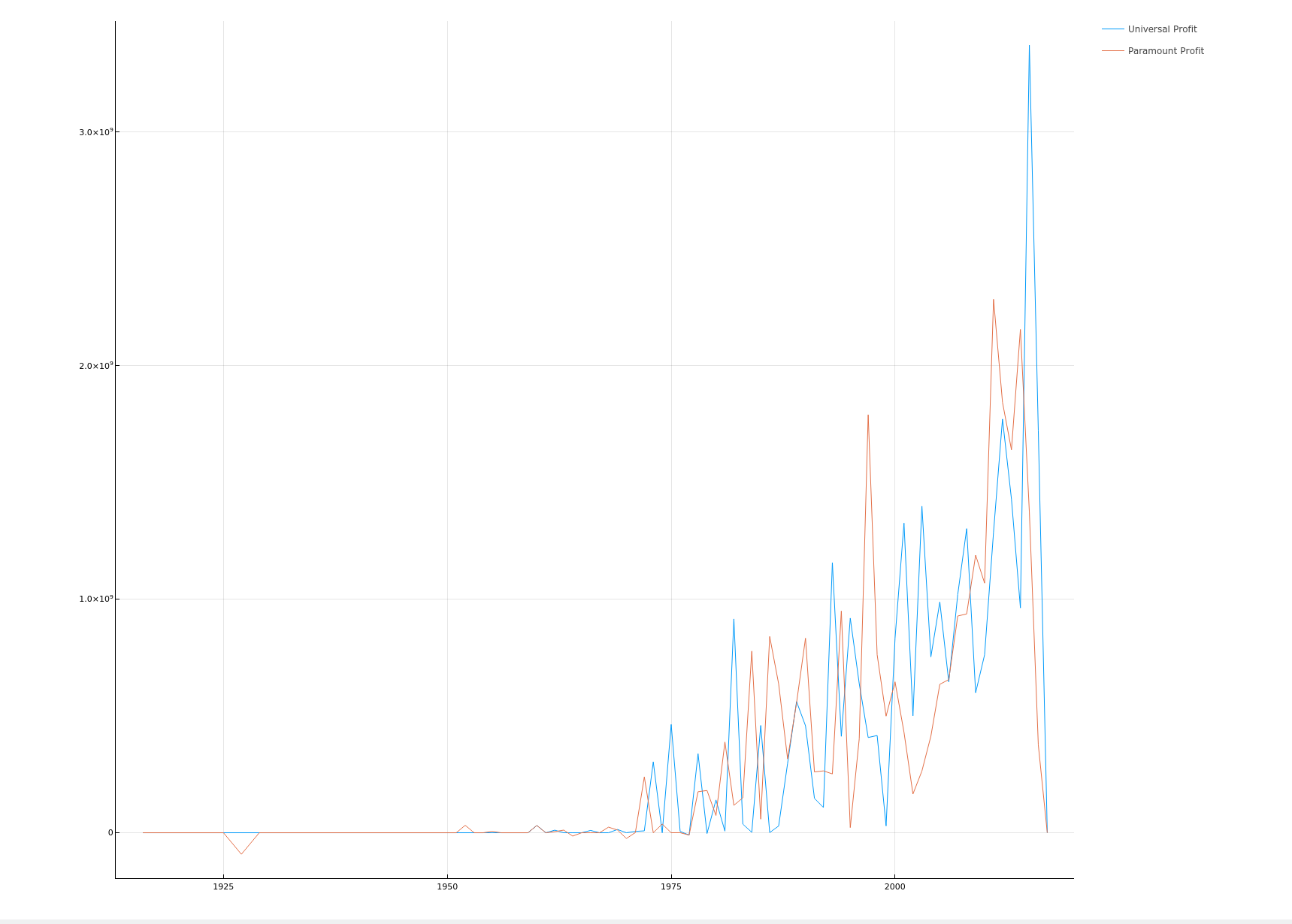
利润对比
function plotCompareProfit(dataframe::DataFrame) dataframe[!, :profit] = dataframe[!, :revenue] .- dataframe[!, :budget] dataframe[!, "Universal Profit"] = dataframe[!, "Universal Pictures"] .* dataframe[!, :profit] dataframe[!, "Paramount Profit"] = dataframe[!, "Paramount Pictures"] .* dataframe[!, :profit] universalProfit = reduce(+, dataframe[!, "Universal Profit"]) paramountProfit = reduce(+, dataframe[!, "Paramount Profit"]) totalProfit = universalProfit + paramountProfit xs = ["Universal Profit", "Paramount Profit"] ys = [universalProfit / totalProfit, paramountProfit / totalProfit] pie(xs, ys) |> display companyDifference = groupby(select(dataframe, vcat(xs, "release_year")), :release_year) # record: Dict{Year, Dict{Company, Number}} record = Dict{Int, Dict{String, Number}}() for _dataframe in companyDifference year = first(_dataframe.release_year) record[year] = Dict{String, Number}() for column in xs profit = reduce(+, _dataframe[!, column]) record[year][column] = profit end end _years = collect(keys(record)) _profitmaps = collect(values(record)) indexs = sortperm(_years) years = _years[indexs] profitmaps = _profitmaps[indexs] p = plot(size = figuresize) for column in xs profits = map(x -> x[column], profitmaps) plot!(p, years, profits, label = column, xticks = :all) end plot(p) |> display end plotCompareProfit(transformedData)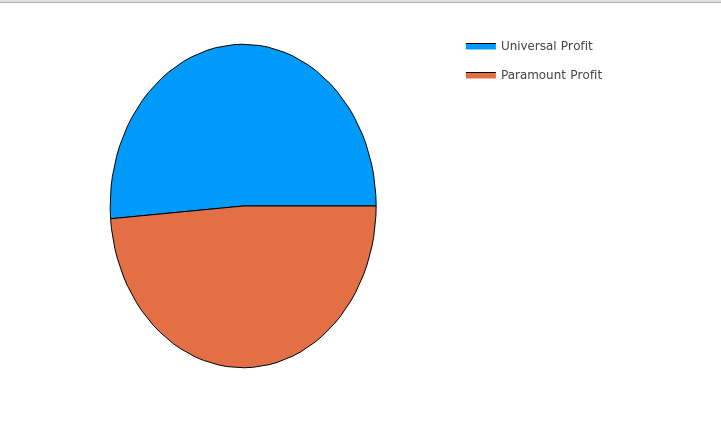
改编电影和原创电影的对比
-
数量对比
function plotCompareOriginal(dataframe::DataFrame) column = "is original" dataframe[!, column] = map(x -> contains(x, "based on novel") ? 0 : 1, dataframe[!, :keywords]) keycount = countmap(dataframe[!, column]) total = keycount[0] + keycount[1] xs = ["is original", "not original"] ys = [keycount[1] / total, keycount[0] / total] pie(xs, ys) |> display end plotCompareOriginal(transformedData)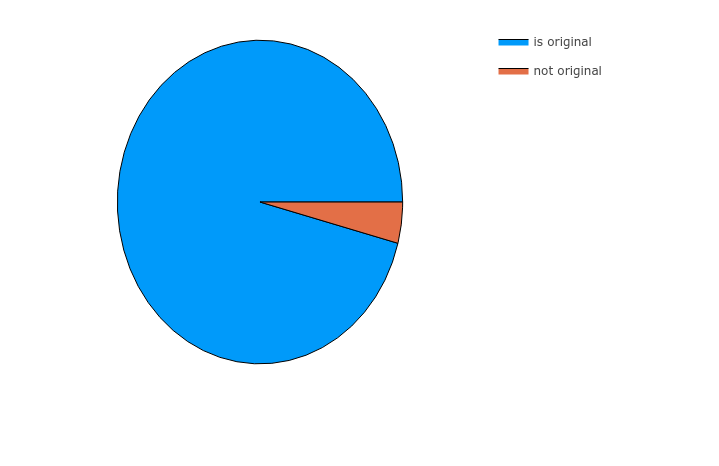
-
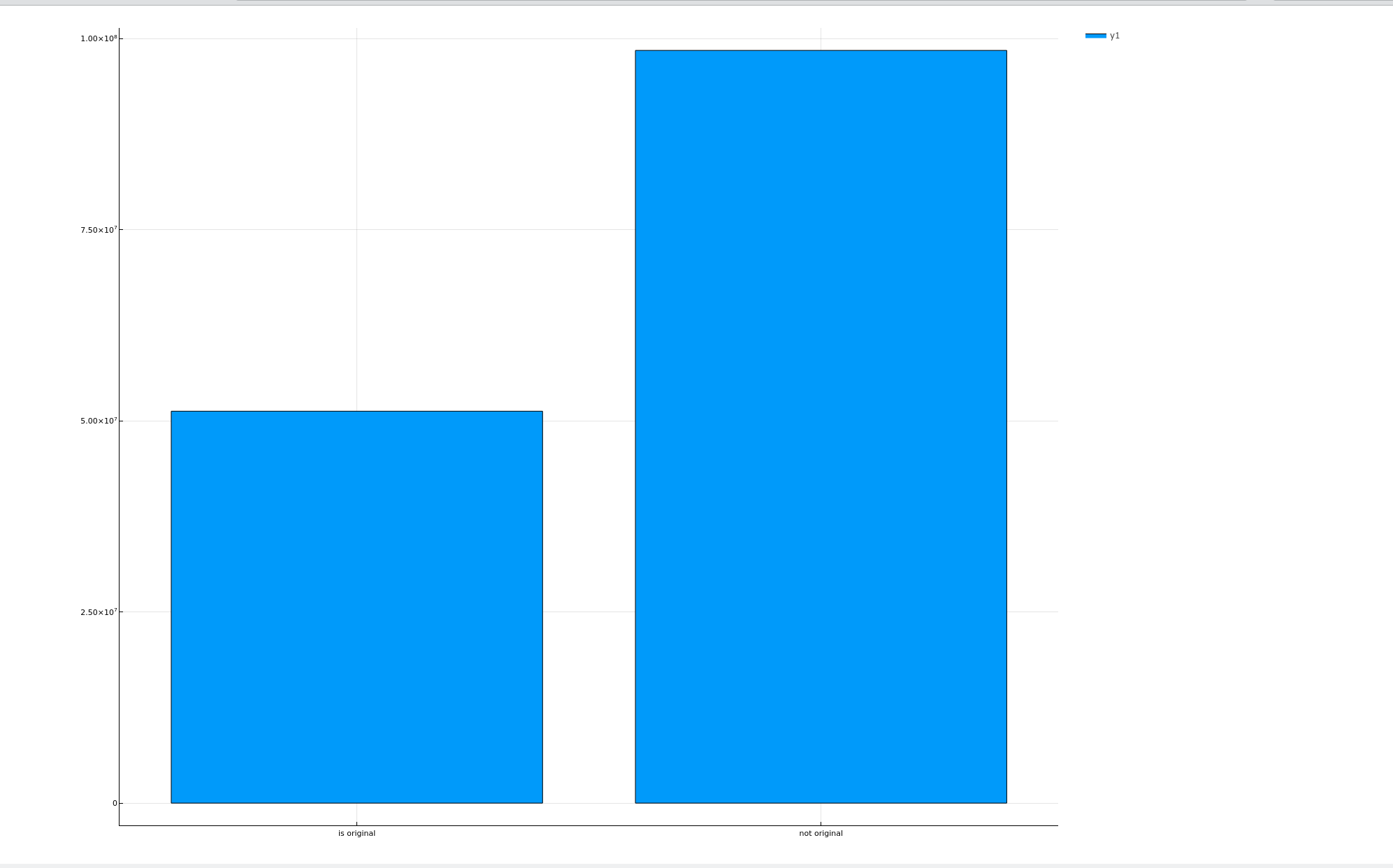
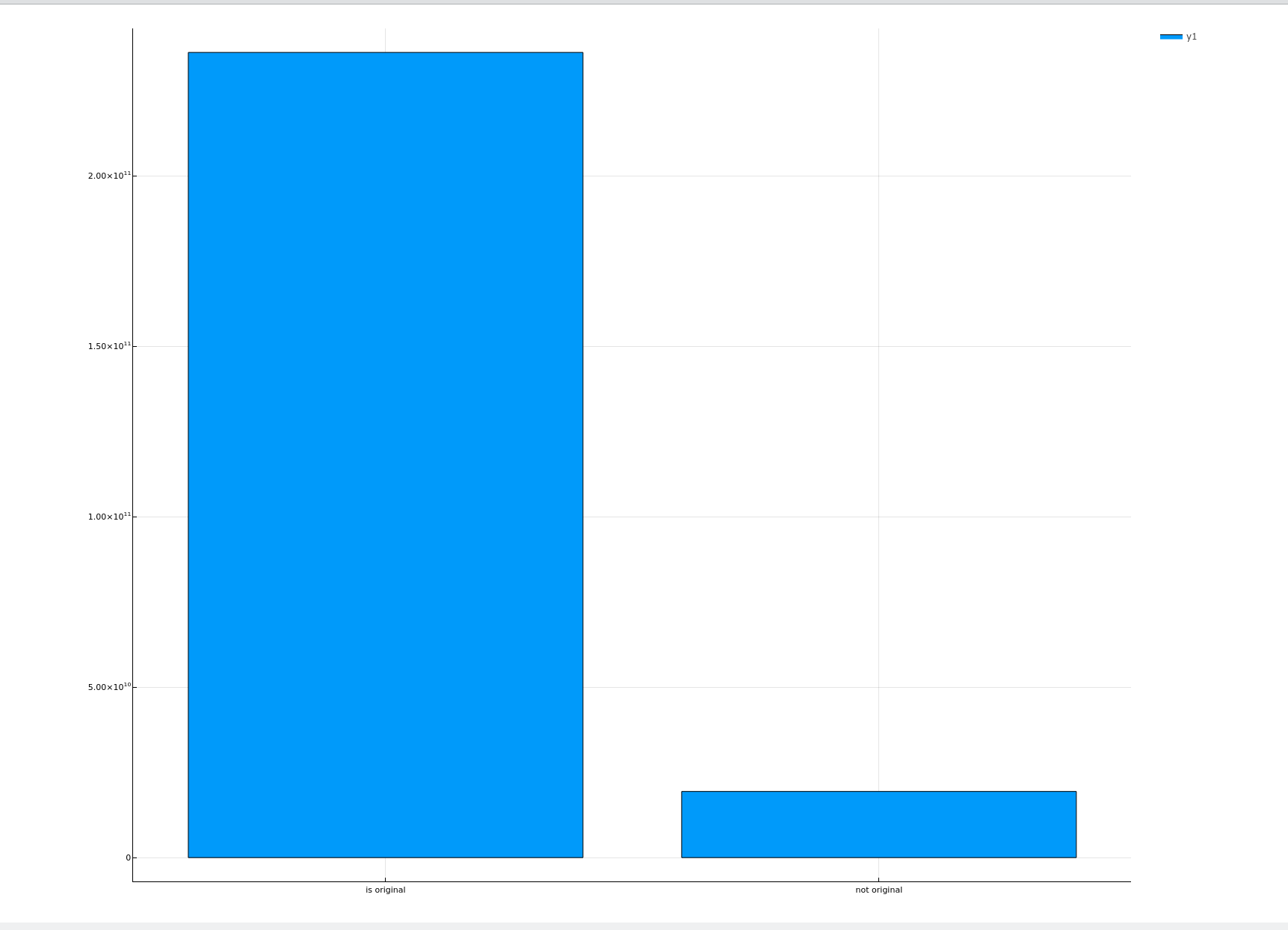
平均利润对比
function plotCompareProfit(dataframe::DataFrame) column = "is original" (notoriginalDataframe, originalDataframe) = groupby(select(dataframe, [column, "profit"]), column) # record: Dict{is original, profit} originalProfit = reduce(+, originalDataframe[!, :profit]) notoriginalProfit = reduce(+, notoriginalDataframe[!, :profit]) originalCount = first(size(originalDataframe)) notoriginalCount = first(size(notoriginalDataframe)) bar(xs, [originalProfit / originalCount, notoriginalProfit / notoriginalCount], size = figuresize) |> display end plotCompareProfit(transformedData)